이 글은 <밑바닥부터 시작하는 딥러닝 2> 책 <8장. 어텐션>을 스터디를 하면서 제가 리딩한 파트를 설명/공유하기 위해 작성하였습니다. 추가적인 설명을 하기 위해 관련 논문이나 아티클 등도 참고하였습니다. 혹시 잘못 작성한 부분이나 코멘트는 댓글로 남겨주세요!
기계 번역의 흐름
- 규칙 기반 번역
- 용례 기반 번역
- 통계 기반 번역
- 신경망 기계 번역(Neural Machine Translate, NMT): 최근에는 seq2seq를 사용한 기계 번역의 총칭으로 사용됨
구글 신경망 기계 번역 (Google Neural Machine Translate, GNMT)

다른 모델과 GNMT와의 차이점
- LSTM 계층의 다층와
- 양방향 LSTM (Encoder의 첫 번째 계층만 적용)
- skip 연결
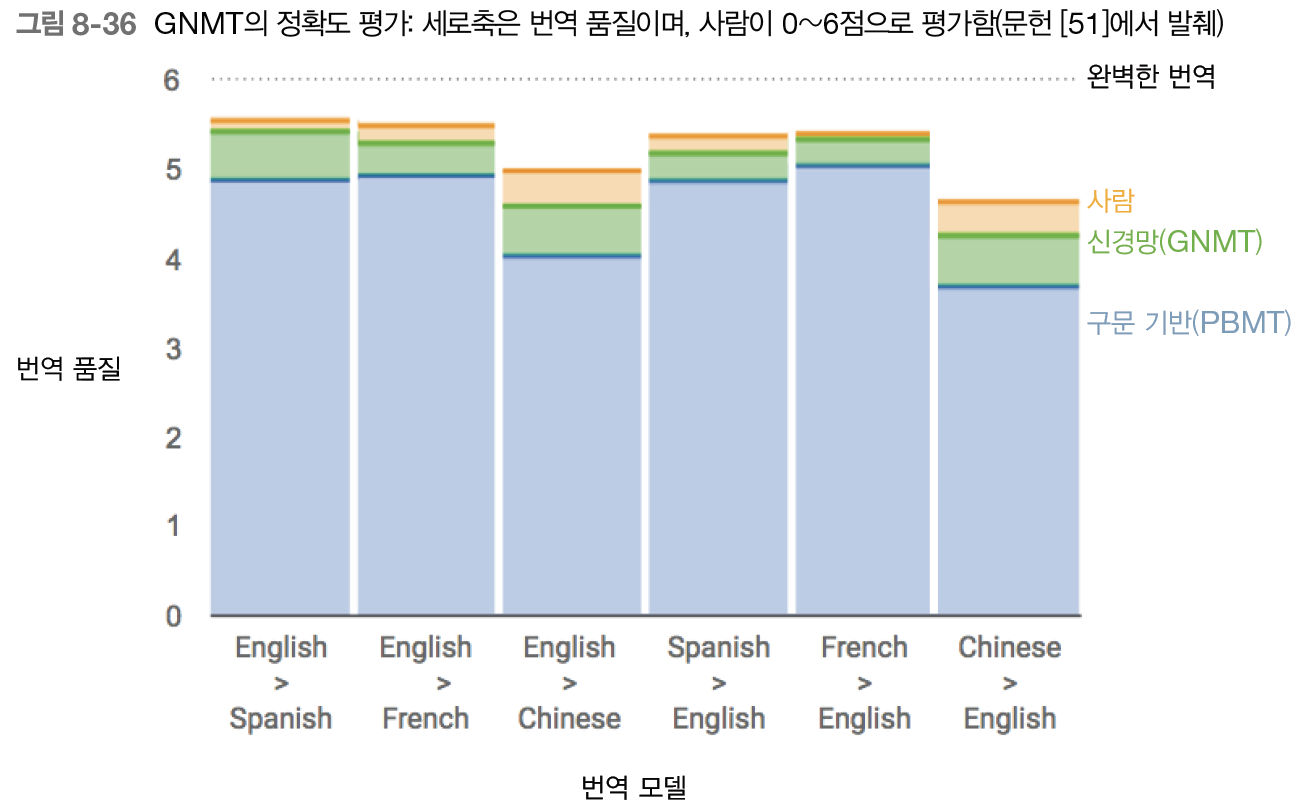
Google's Neural Machine Translatgion System 요약
1. NMT의 고질적인 단점
- 학습과 추론(inference) 과정에 속도가 매우 느림
- 학습에 사용되지 않은 사용 빈도가 낮은 단어(rare words)가 있는 문장을 번역할 경우, 그 문장 전체를 번역 실패할 수 있음
- 이는 'Copy Model'을 활용하여 문제를 해결함
- 학습 데이터셋이 매우 방대하여 파라미터가 많기 때문에, 학습(training) 과정에서 상당한 시간과 컴퓨팅 자원을 요구됨
2. GNMT 모델 아키텍쳐 및 특징
-
Attention 네트워크 기능을 적용함
-
seq2seq 모델로, 8개의 LSTM Encoder와 LSTM Decoder로 이루어져 있음
- Decoder 마지막 단계에서는 LSTM과 Softmax를 사용하여 최종적인 단어를 선택함
-
정확도를 높이기 위해 LSTM stack에 Residual 노드를 넣음
- Simple stacked LSTM 모델로 학습할 경우, Gradient exploding / vanishing 문제가 발생함
- 경험상 학습 데이터셋이 많은 경우, 4개의 레이어에는 잘 동작하며 드물게는 6개의 레이어까지도 괜찮음. 8개 레이어에서는 성능이 좋지 않음.
- Simple stacked LSTM 모델로 학습할 경우, Gradient exploding / vanishing 문제가 발생함
-
맥락을 충분히 살피기 위해 Encoder 모델의 마지막 레이어(bottom layer)에는 양방향(Bi-directional) RNN을 사용함
-
첫번 째 레이어에만 적용함
-
모델 병렬화와 데이터 병렬화를 모두 사용함
-
데이터 병렬화를 위해 Downpour SGD *를 사용함
- * Donwpour SGD: 데이터 병렬화를 위해 만들어진 알고리즘으로, 모델을 여러 개로 나누어 동시에 여러 모델을 학습한 후 나온 Gradient 값의 평균을 각각의 모델에 적용함
-
NMT는 고정된 사전 집합을 사용하기 때문에, 사전에 포함되지 않은 단어가 등장하면 OOV(Out of vocabulary) 문제가 있음
-
OOV를 해결하기 위해 Copy 모델을 사용함: 해석되지 단어는 입력에서 바로 출력으로 전달함
-
이를 개선하기 위해 sub-word unit을 만드는 방식의 WPM(Wordpiece model) 추가함
- Word: Jet makers feud over seat width with big orders at stake
- wordpieces: _J et _makers _fe ud _over _seat _width _with _big _orders _at _stake
- 연산 처리 속도를 향상하기 위해, Quntized inference를 사용함
- Perplexity에는 큰 차이가 없지만, TPU(Tensor Processing Unit)의 Decoding time이 확연하게 줄어듦
Downpour SGD: Downpour SGD는 DistBelif라는 구글의 모델, 데이터 병렬화 학습 모델에서 소개된 방법이다. 간단히 말하면 여러개로 모델을 쪼개어, 여러개의 머신에서 동시에 학습을 하는데 이 때 여러 모델들에서 계산된 gradient를 평균내서 각각의 모델에 적용하는 방법이다. 이렇게 해도 충분히 전체 데이터와 모델에 대한 근사적인 학습이 가능하다고 하다.
출처: https://newsight.tistory.com/224 [New Sight]
Downpour SGD: Downpour SGD는 DistBelif라는 구글의 모델, 데이터 병렬화 학습 모델에서 소개된 방법이다. 간단히 말하면 여러개로 모델을 쪼개어, 여러개의 머신에서 동시에 학습을 하는데 이 때 여러 모델들에서 계산된 gradient를 평균내서 각각의 모델에 적용하는 방법이다. 이렇게 해도 충분히 전체 데이터와 모델에 대한 근사적인 학습이 가능하다고 하다.
출처: https://newsight.tistory.com/224 [New Sight]
3. GNMT 연구 의의
- wordpeice(sub-word units) 모델링은 번역의 품질(quality)과 추론 속도를 개선하기 위해, open vocabularies와 형태학적으로 풍부한 단어에 대한 도전(?)을 효과적으로 다룸
- 모델 병렬화와 데이터 병렬화는 약 일주일 내에 최첨단 seq2seq NMT 모델을 효율적으로 학습할 수 있음
- 길이 정규화(length-normalization), 커버리지 패널티(coverage penalties), 유사성(similar)과 같이 추가적인 세부사항은 실제 데이터와 NMT 시스템을 제대로 작동하는 데 필수적임!
GNMT 연구 결론
GNMT는 구문 기반(Pharse-based) 번역 시스템 보다 오류율을 약 60% 감소시켰다! (영어 <-> 불어, 스페인어, 중국어 기준)
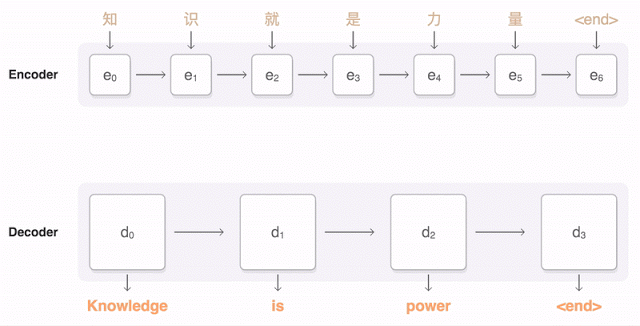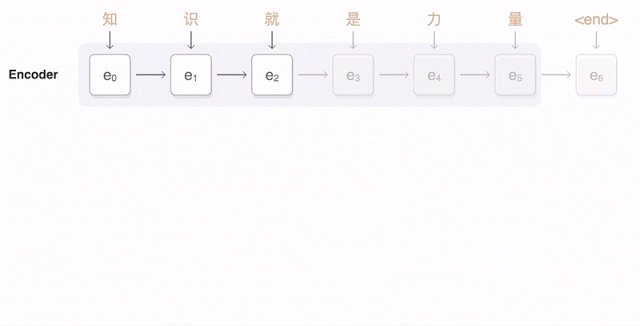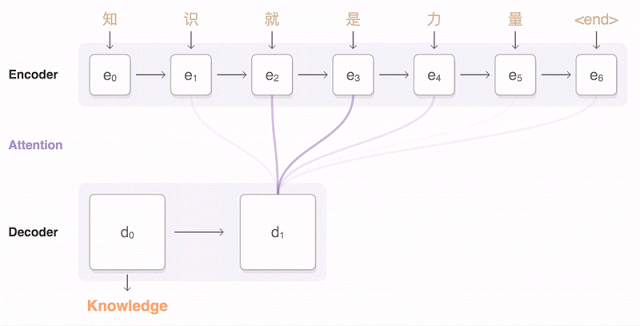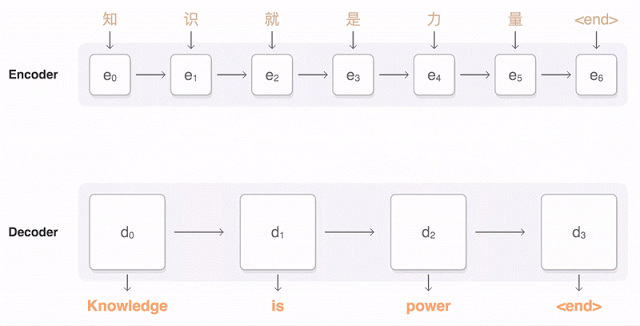
추가적인 GNMT의 번역 결과 예제는 <ExampleTranslation.pdf>에서 확인할 수 있습니다.
References
- GNMT 페이퍼 전문에 대한 요약글 <Google's Neural Machine Translation System. 논문 요약글>
Google's Neural Machine Translation System.
그리고 \(sigmoid, tanh\) 등의 함수와 element-wise 연산인 \( (\odot, +) \) 등도 모두 정수에 대한 연산으로 수행된다.
norman3.github.io
- Google 블로그에 소개된 GNMT <Google AI Blog: A Neural Network for Machine Translation, at Prodution Scale>
'20. 인공지능과 딥러닝' 카테고리의 다른 글
| [인공지능을 위한 선형대수] 선형독립과 선형종속 (0) | 2019.09.01 |
|---|---|
| [인공지능을 위한 선형대수] 선형결합 (Linear combination) (0) | 2019.09.01 |
| 밑바닥부터 시작하는 딥러닝 2 :: Ch 08 어탠션 (3) seq2seq2 심층 + skip 연결 (0) | 2019.07.14 |
| 밑바닥부터 시작하는 딥러닝2 :: Ch 08 어텐션 (2) 양방향 LSTM (0) | 2019.07.14 |
| 밑바닥부터 시작하는 딥러닝2 :: Ch 08. 어텐션 (1) 어텐션 구조 (0) | 2019.07.14 |



댓글