edwith의 [부스트코스] 파이토치로 시작하는 딥러닝 기초의 Dropout 강의를 정리한 내용입니다.
[LECTURE] Lab-09-3 Dropout : edwith
학습목표 드롭아웃(Dropout) 에 대해 알아본다. 핵심키워드 과최적화(Overfitting) 드롭아웃(Dropout) - tkddyd
www.edwith.org
Overfitting
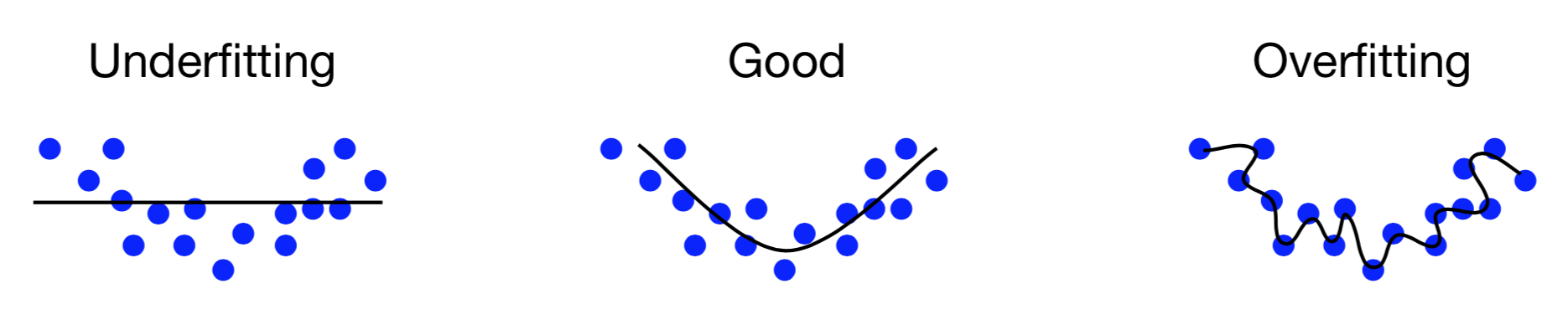
데이터를 잘 fitting 시키는 게 목표라고 할 때, 위 그림의 왼쪽 'Underfitting' 모습처럼 선형으로 분리를 하면 적합하지 않을 수 있다. 반면 고차원(highdimension)으로 표현할 경우, 'Overfitting' 모습처럼 주어진 데이터에만 집중한 것을 알 수 있다.
오른쪽 Overfitting처럼 주어진 데이터를 잘 표현하는 게 왜 문제가 될까?
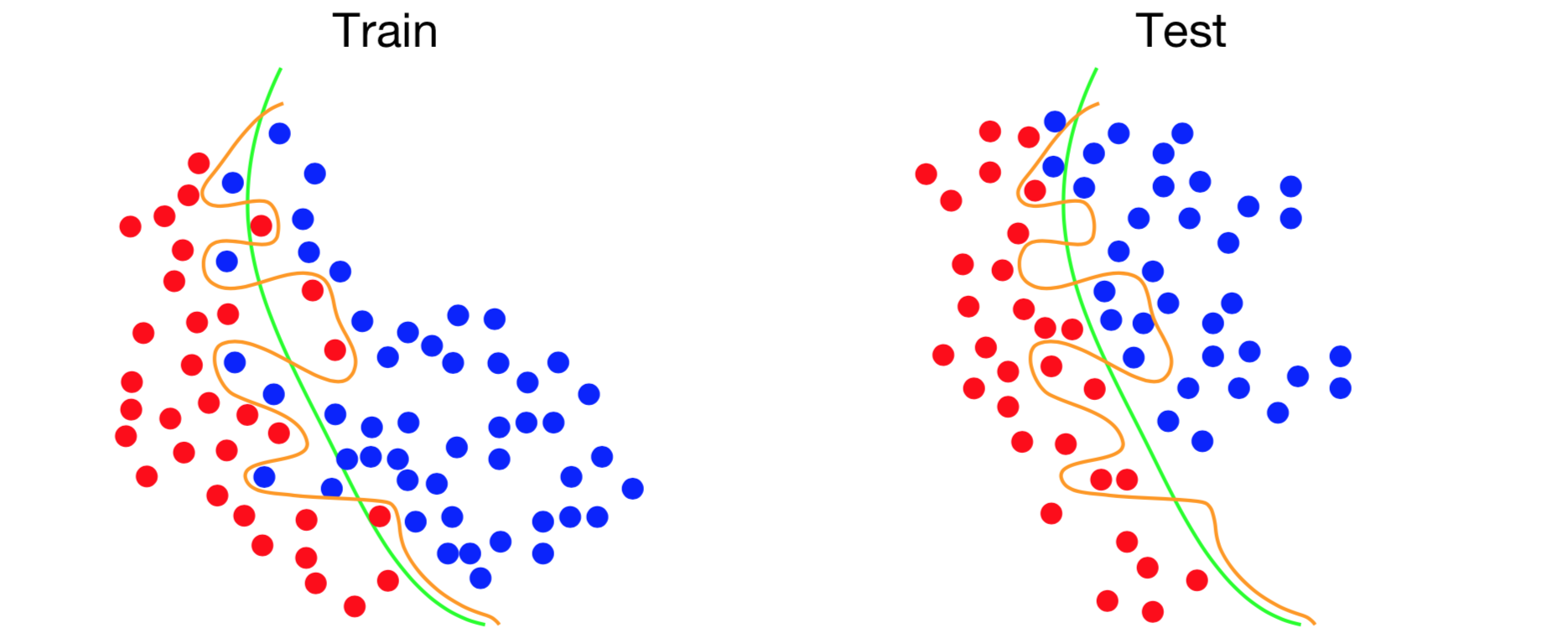
위 그림처럼, trian-set과 test-set이 완벽하게 일치하지 않는다.
train-set에서는 한 번도 보지 못한 데이터가 있을 수 있기 때문에, train-set에 집중하게 되면 실제로 분류했을 땐 오분류가 나타나 성능이 좋지 않을 수 있다.
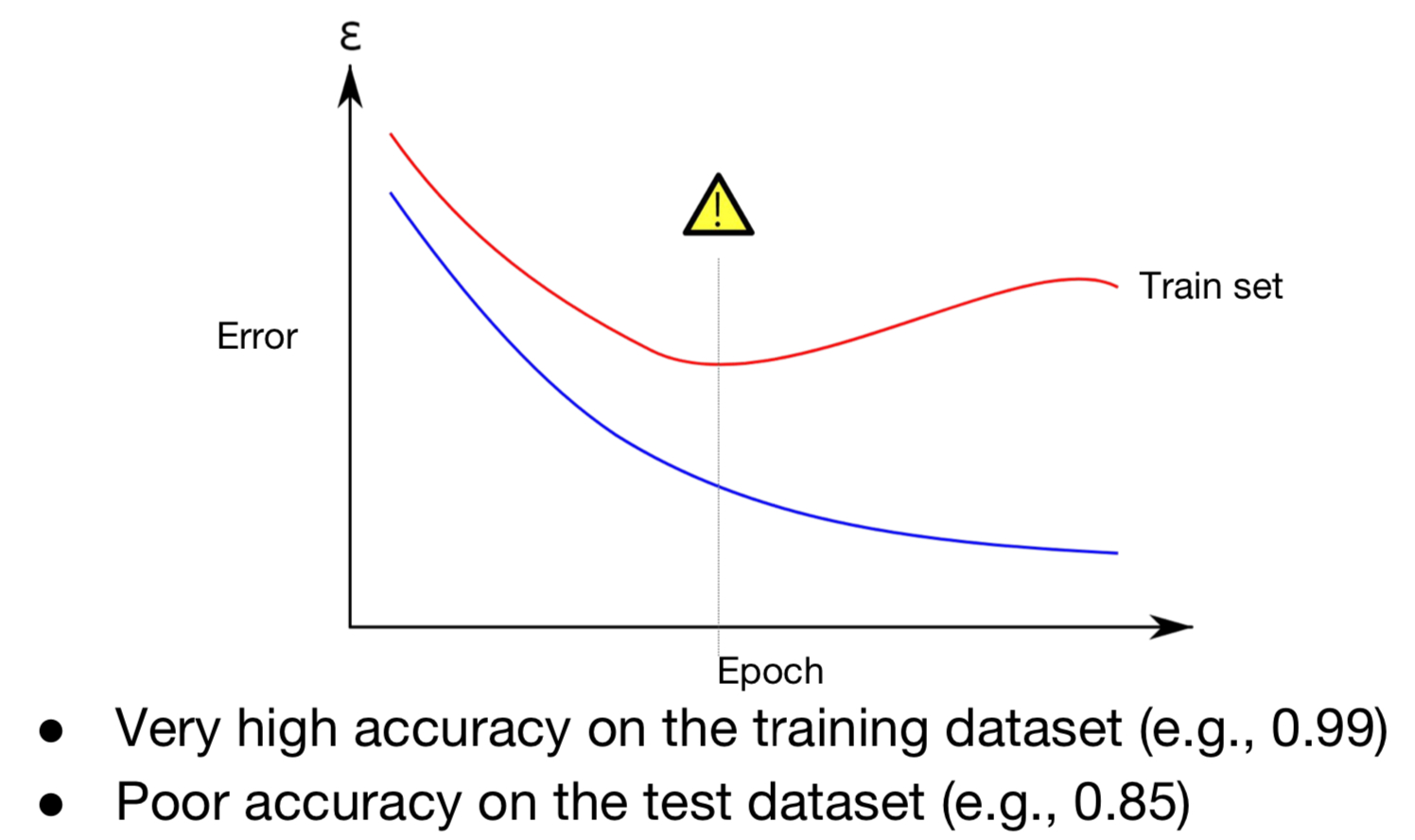
Train-set에서는 정확도가 매우 낮지만, 실제 환경인 Test-set에서는 정확도(accuracy)는 낮고, 오류율은 증가하게 된다. 이러한 문제가 overfitting의 문제이다.
Solutions for overfitting
- 학습셋을 늘린다.
- Feature의 개수를 줄인다.
- Regularization term을 추가한다.
- Dropout! (이번 강의에서 다룰 개념)
Dropout

(a) 기본적인 인공신경망(standard neural net) ouput과 gradient loss 간의 차이(=loss)를 구한 뒤, backpropagation 알고리즘을 구하여 weight를 업데이트하는 방식이다.
(b) 뉴런이라고 부르는 노드를 무작위로 껐다 켰다를 반복하는 것을 dropout이라고 한다.
예를 들어, 학습 데이터 x가 주어졌을 때, 각 레이어별로 x 데이터의 사용 여부를 결정하는 것이다. (b) 그래프에서 첫 번째 레이어를 보면 2, 3번째 노드 x를 사용하지 않은 것을 볼 수 있다. 두 번쩨 레이어에서는 1, 3,4번째 노드는 사용하지 않았다. 최종적으로 세 개의 weight만 이용하여 계산하게 되고, ouput과 G(t) 간의 차이를 이용해 loss를 구한 뒤, backpropagation 하여 값들을 업데이트한다.
Dropout의 효과
Dropout을 사용하면 (1) overfitting을 방지할 수 있으며, (2) 성능을 향상할 수 있다. 매번 다른 형태의 노드로 학습하기 때문에, 여러 형태의 네트워크들을 통해서 (3) 앙상블 효과를 낼 수도 있다.
Code: mnist_nn_dropout
# nn Layers
linear1 = torch.nn.Linear(784, 512, bias=True)
linear2 = torch.nn.Linear(512, 512, bias=True)
linear3 = torch.nn.Linear(512, 512, bias=True)
relu = torch.nn.ReLU()
dropout = torch.nn.Dropout(p=drop_prob) # 사전에 정의한 어떤 특정 확률에 따라서 무작위로 선택하는 과정
#model = torch.nn.Sequential(linear1, relu, dropout,
linear2, relu, dropout,
linear3, relu, dropout).to(device)- (p = drop_prob)
노드를 얼만큼 활용 안 할지('할지' -> '안 할지' 2020-06-06 정정함 ) 무작위로 선택하기 위해 사용한다.
Dropout을 사용할 때 주의할 점
...
total_batch = len(data_loader)
model.train() # 학습 모드에서는 드롭아웃을 사용함 (dropout=True)
for epoch in range(training_epochs):
...
...
# Test model and check accuracy
with torch.no_grad():
model.eval() # 검증 모드에서는 사용하지 않음 (dropout=False)
...- model.train()
(Trian mode) 학습할 땐 무작위로 노드를 선택하여 선별적으로 노드를 활용함 - model.eval()
(Evalutaion mode) 평가하는 과정에서는 모든 노드를 사용하겠다는 의미
model.train()과 model.eval()을 꼭 선언을 해야지 모델의 정확도를 높일 수 있다.BatchNorm에서도 사용한다.
자세한 내용은 Pytorch 홈페이지 글을 참고하세요!
댓글