하둡 강의를 들으면서 빠르게 메모한 내용입니다.
예쁘게 정리해서 발행하고 싶었으나 게으름을 이기지 못하고 오랫동안 방치하다가, 누군가에게는 도움이 될 수도 있지 않을까 기대하며 공개발행으로 전환하였습니다.
출처 :
[토크ON세미나] 아파치 하둡 입문 5강 - 하둡 맵리듀스 | T아카데미
맵리듀스
Map Function : key1, value1 -> key2, value2
Reduce Function : key2, LIst of value2 -> key3, value3

YARN : 2.0
클라이언트
잡 트래커
태스크 트래커
하둡분산파일시스템

분산 저장 -> Map -> Merge, Sort -> (Map task) -> Reduce
Mapper 필수
Reducer 옵션
Shuffle / sort 단계 : 다른 맵의 데이터를 머지하는 과정이므로 트래픽이 많음 -> 트레픽 양을 최소한으로 줄여주는 게 중요
-> 컨바이너, Partitioner
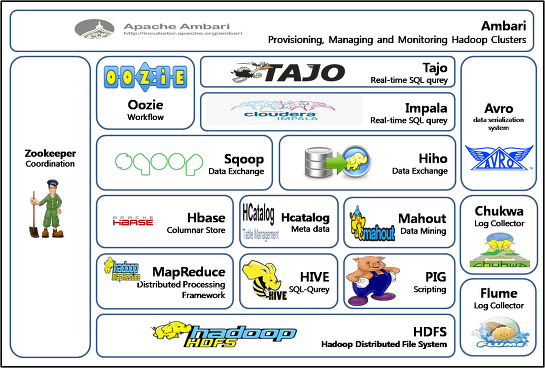
하둡 2.0 YARN
YARN : 클러스터 리소스 매니저 -> MapReduce, Others (e.g., MPI)
Hadoop 3.0
Erasure Coding 피지컬하게 300mb -> 200mb 줄여주는 기능
파일 크기가 큰 경우, 용량을 절반으로 줄어드는 효과를 기대할 수 있음
'30. Cloud' 카테고리의 다른 글
| [토크ON세미나_아파치 하둡 입문 4/4] 하둡 활용 (0) | 2022.01.23 |
|---|---|
| [토크ON세미나_아파치 하둡 입문] HDFS 이해 2 (0) | 2022.01.23 |
| [토크ON세미나_아파치 하둡 입문 1/3] HDFS 하둡 분산 파일 시스템 (0) | 2022.01.22 |
| [AWS SA-CO2] AWS EC2 (0) | 2021.08.01 |
| [SAA-CO2] AWS 스토리지 (0) | 2021.07.31 |

댓글