이 글은 주재걸 교수님의 <인공지능을 위한 선형대수> edwith 강의를 기반으로 선형대수 개념을 정리하였습니다.
www.edwith.org
Transformation 개념
- Transformation
- Function
- Mapping
- Domain: 정의역 x
- Co-domain: 공역 y (함수의 출력값이 될 수 있는 결과값의 집합)
- Imange: 함수의 상 (output y given x)
- Range: 치역 (실제로 y 값으로 쓰이는 값)
함수의 특징
- 정의역은 하나의 화살표만 있어야 한다.
- 함수 값이 두 개 이상일 수 없다.
- the output mapped by a particular x is uniquely determined.
-> 이 조건을 충족하지 않으면 함수(function)라고 부를 수 없다.
Linear Transformation
Linear Transformation 정의

주어진 정의역에서 원소 두 개를 뽑아 선형결합해서 나오는 함수(해당 벡터)가 선형결합을 나중에 했을 때의 함수값과 정확하게 일치하면 "선형 변환(linear transformation)"이라고 한다.

3과 6을 선형결합에 썼던 계수(x1, x2)를 결합하여 값이 같으면 선형변환의 조건이 된다.
Q. y = 3x + 2 는 선형결합일까?
x = 1 -> y = 5, x = 2 -> y = 8
3*1 + 4*2 = 11 => 3x + 2 함수에 집어 넣는다면 3*11 + 2 = '35'가 된다. 3*5 + 4*8 = 47은 35가 되지 않기 때문에 '선형결합이라고 하지 않는다.
Transformations between Vectors
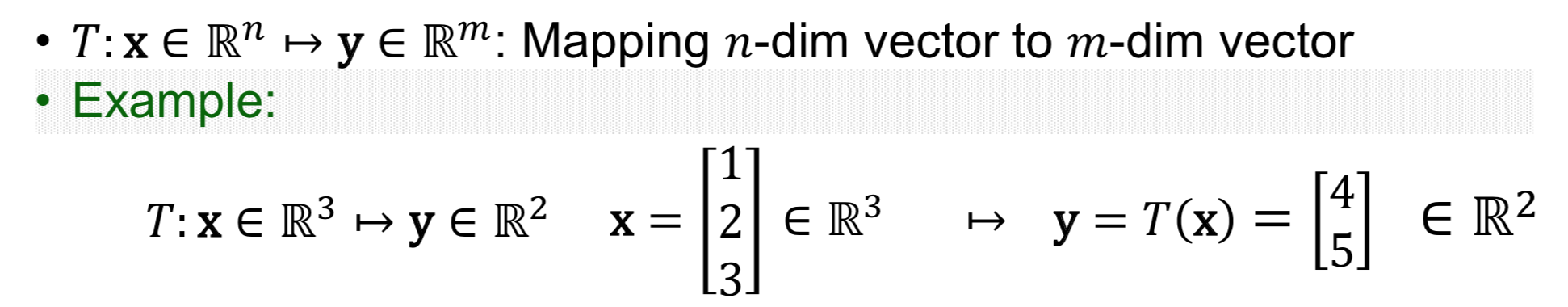
Matrix of Linear Transformation

Linear Transformation with Neural Network
다음은 신경망에서 선형변환이 어떻게 적용됐는지 알아보자.
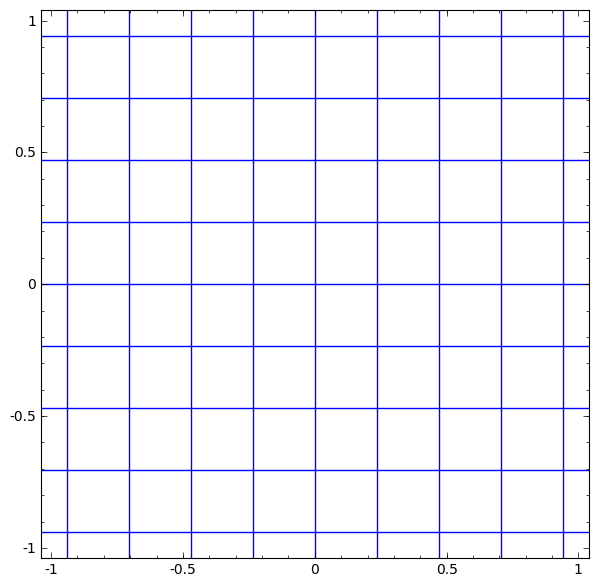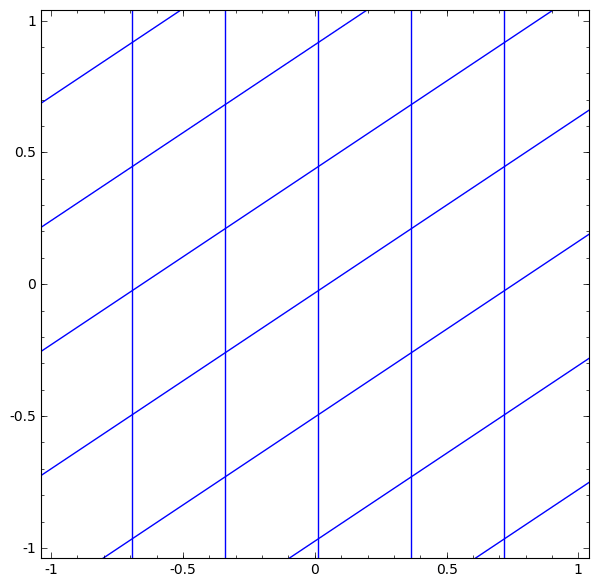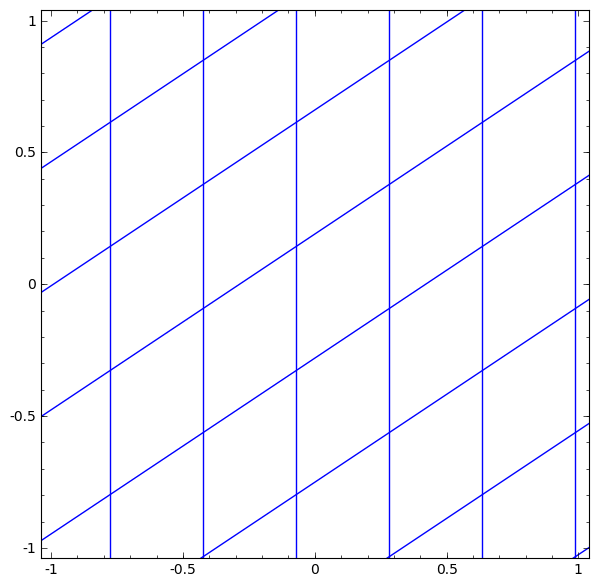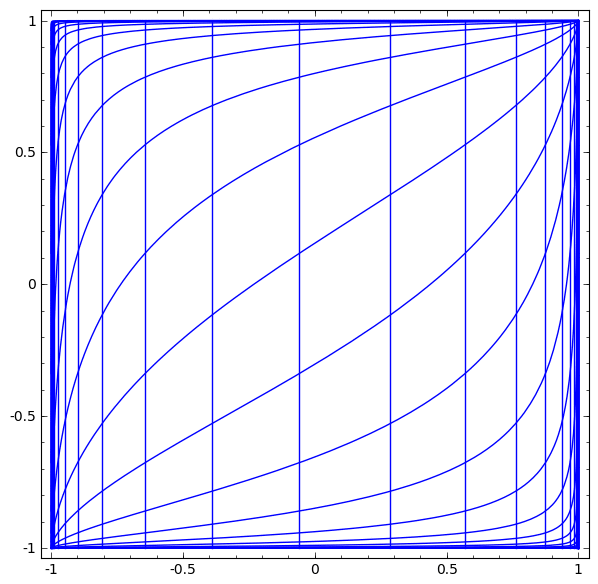
2차원에서 변환이되는 레이어를 생각해 볼 때, A(계수들의 집합)의 변환은 [1, 0]과 [0, 1]을 넣어본다. 정사각형을 기울어진 평행사변형으로 만든다고 생각하면 된다. (평행사변형 모양의 모눈종이를 만드는 게 선형변환에서 발생하는 일이다!)
- 모눈종이를 구기는 과정은 non-linear 때문에 발생하며, 선형변환을 통해서 평행사변형 모눈종이로 바뀐다.
- '0' 근처는 그대로 유지되대, '0'에서 멀어지는 부분은 압축을 시켜 값을 작게 만드는 역할을 한다.
- 선형변환으로 쭉 펴진 다음에, 옆으로 흐르는 느낌은 bias-term 때문에 발생하는 과정이다.
Affine Layer in Neural Networks
y = 3x + b 는 bias가 있기 때문에 선형변환은 아닌, Affine Transformation이라고 한다.

Affine Layer (=Fully connected layer) + bias
입력벡터를 3차원으로 만드는 Matrix + bias(상수 벡터) = output (Sigmod 등을 통해서 non-linear 통과 후 output이 나옴)
Affine Transformation (Colum combination으로 변환하는 과정)
5개의 벡터에 bias에 계수 1을 붙인 후(1 은 붙여도 상관없기 때문에), 메트릭스와 벡터의 곱으로 복원한다. 이 과정에서 bias term 까지 포함하여, 입력벡터에 쓰였던 픽셀값(56, 231, 24, 2)과 bias '1'까지 포함하여 Ax 형태로 만들어 준다.
* bias term은 처음 또는 마지막 차원에 '1'을 끼워넣어 해결한다.
예)
input node: 키, 몸무게, 흡연 여부 (=feature) -> output node: 당뇨병일 확률, 고혈압일 확률, 폐암일 확률
=> Input node(키)가 colum의 상수배(e.g., 0.2, 1.5, -0.2) 만큼 node에 전파를 하는 과정
참고 아티클
Neural Networks, Manifolds, and Topology
Neural Networks, Manifolds, and Topology -- colah's blog
Neural Networks, Manifolds, and Topology Posted on April 6, 2014 topology, neural networks, deep learning, manifold hypothesis Recently, there’s been a great deal of excitement and interest in deep neural networks because they’ve achieved
colah.github.io
'20. 인공지능과 딥러닝' 카테고리의 다른 글
| [인공지능을 위한 선형대수] Least Squares Problem(최소자승법) 소개 (0) | 2019.09.24 |
|---|---|
| [인공지능을 위한 선형대수] 전사함수와 일대일함수(단사함수) (0) | 2019.09.07 |
| [인공지능을 위한 선형대수] 부분공간의 기저의 차원 (0) | 2019.09.04 |
| [인공지능을 위한 선형대수] 선형독립과 선형종속 (0) | 2019.09.01 |
| [인공지능을 위한 선형대수] 선형결합 (Linear combination) (0) | 2019.09.01 |



댓글