최근 chatGPT, 미드저니 등 생성형 AI가 적용된 서비스들이 많이 등장하면서, 이미지를 생성하는 Stable Diffuion 서비스에 적용된 Diffusion model의 동작 방식과 개념에 대해서 간단히 알아보고자 한다.
Generative Model
생성형 AI 모델은 분류 모델과 달리, 낮은 차원의 데이터에서 높은 차원의 데이터를 만들어내는 과정을 거친다. 대표적인 방식으로 GAN, VAE, Flow 기반 모델, Diffusion 등이 있다. 각 모델마다 이미지를 생성하는 방식이 조금씩 다르다.
VAE(Variational AutoEncoder)는 Auto Encoder 방식에서 파생된 모델이다. encoder의 입력값을 특정 확률 분포의 한 점으로 만들고, decoder에서 한 점으로부터 입력값을 생성하여, 숨겨진 벡터 latent space를 도출한다. Latent space에서 원하는 output을 decoding하며 데이터를 생성하는 방식이다.
GAN(Generatvie Adversarial Network)은 데이터 생성자(generator)와 실제 데이터인지 생성한 데이터인지 판별하는 판별자(discriminator)를 동시에 학습하는 방식이다. 이 모델은 위조지폐범과 경찰의 관계처럼, 최대한 실제와 같은 데이터를 생성하여 판별자를 속이려고 하며, 판별자는 실제 데이터와 가짜 데이터를 구별하려고 노력한다.
Flow 기반 모델은 단순한 확률 분포에서 추출된 값을 여러 과정에 거쳐 변환하여 복잡한 분포를 만드는 방식이다. 여러 단계의 가역함수를 거쳐 아웃풋을 만든다.
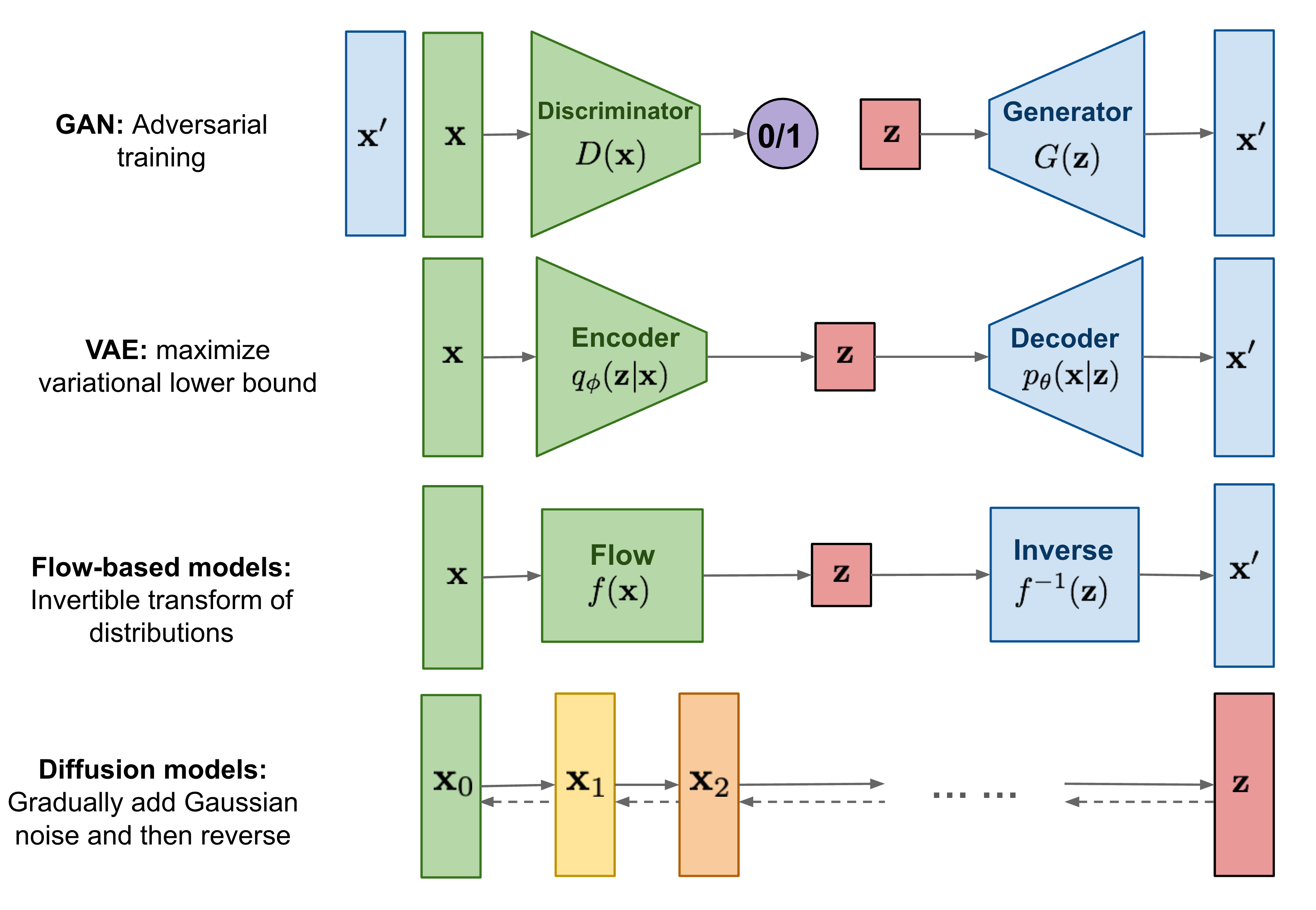
Diffusion Model
스테이블 디퓨전은 확률론적 모델링 기술을 이용하여 불안정성을 해결하고, 안정적인 이미지를 생성하는 Diffusion model 방식으로 이루어져 있다. 이 모델은 물리학의 랑주뱅 동역학(Langevin dayamics)에서 아이디어를 얻었다.
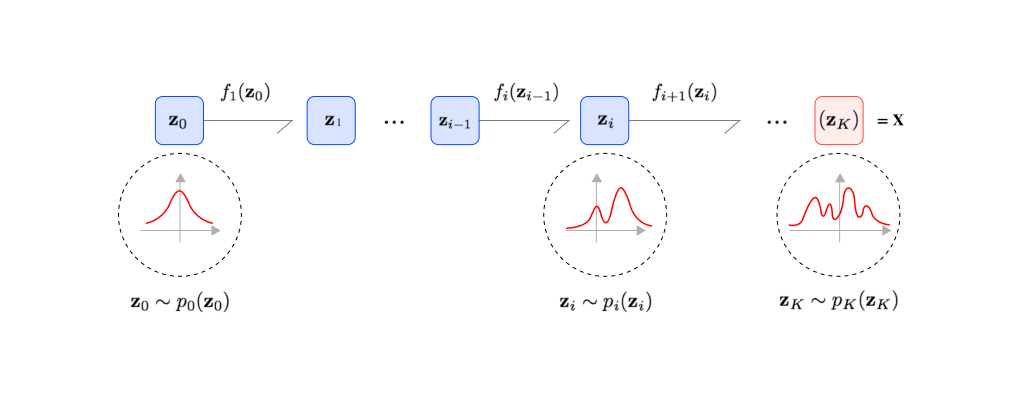
Diffusion model에서 주어진 데이터 x에서 노이즈를 만드는 과정을 Forward Process (Diffusion Process)이라고 한다. 반대로, 노이즈를 복원하여 데이터를 만드는 과정은 Reverse Process 이다. Reverse diffusion proecess를 학습하는 과정으로, 데이터에서 노이즈를 제거한다.
Forward Process (Diffusion Process)
이미지를 생성하는 과정을 요약하면 아래와 같다.
- x0 : 실제 데이터
- xT : 최종 노이즈
- xt : 데이터에 노이즈가 더해진 상태 (Latent Variable)

오른쪽에서 왼쪽 방향으로 노이즈를 더하는 Forward Process q 과정과 Foward Process 반대 과정으로 진행되는 Reverse Process p를 학습한다. 이 과정에서 noise(xT)에서 data(x0)을 복원하는 과정을 학습한다.
Reverse Process를 활용하여, Random Noise에서 우리가 원하는 이미지, 텍스트 등을 생성할 수 있는 모델을 만든다. 즉, 실제 데이터의 분포인 p(x0)을 찾는 것을 목표로 한다.
Reverse Process
Reverse Process에서 p는 noise(xT)에서 data(x0)를 복원하는 과정으로, Generative model이 된다. Forward process에서 분포를 Gaussian distribution으로 정의하였지만, 반대 방향은 distribution을 알 수 없는 상태이다. 따라서, distribution은 pθ를 이용하여 Gaussian Transition을 활용한 Markov Chain 방식으로 approximate 한다.
Training과 Loss
생성형 모델은 distribution estimate하는 것, 즉 실제 데이터의 분포인 pθ(x0)를 찾고 likelihood를 최대화하는 것이 목적이다. 주어진 데이터 x에서 likelihood를 계산하여 판단할 수 있다. 학습한 negative log-likelihood의 ELBO를 사용한다.
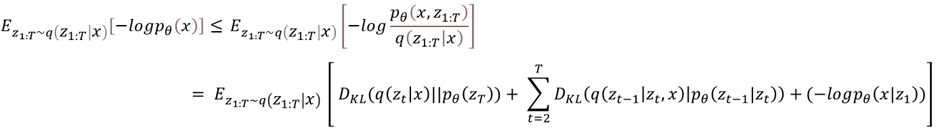

참고 자료
[1] Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33, 6840-6851.
[2] https://www.lgresearch.ai/blog/view?seq=190&page=1&pageSize=12
[NeurIPS 2021] 1편: Generative model - Diffusion model Review | LG AI
‘NeurIPS 2021(Conference and Workshop on Neural Information Processing Systems 2021, 신경정보처리시스템학회)’은 1987년에 처음 시작된 학회로, AI와 머신러닝 분야의 가장 권위 있는 학회 중 하나입니다. 약 20%의
www.lgresearch.ai
[3] https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
What are Diffusion Models?
[Updated on 2021-09-19: Highly recommend this blog post on score-based generative modeling by Yang Song (author of several key papers in the references)]. [Updated on 2022-08-27: Added classifier-free guidance, GLIDE, unCLIP and Imagen. [Updated on 2022-08
lilianweng.github.io
[4] https://process-mining.tistory.com/182
Diffusion model 설명 (Diffusion model이란? Diffusion model 증명)
Diffusion model은 데이터를 만들어내는 deep generative model 중 하나로, data로부터 noise를 조금씩 더해가면서 data를 완전한 noise로 만드는 forward process(diffusion process)와 이와 반대로 noise로부터 조금씩 복
process-mining.tistory.com
'20. 인공지능과 딥러닝' 카테고리의 다른 글
| 미드저니 Midjourney 사용 방법 & 파라미터 설정하기 (1) | 2023.05.18 |
|---|---|
| 2023 Google I/O : 인공지능, 검색엔진, 하드웨어 (0) | 2023.05.17 |
| 오토인코더의 모든 것 (1/3) 03. Autoencoders (1) | 2022.03.26 |
| [인공지능 및 기계학습 개론 II] Latent Dirichlet Allocation 모델 (0) | 2020.11.29 |
| Asynchronous Methods for Deep Reinforcement Learning (A3C) (0) | 2020.09.14 |




댓글